![]()

Machine Learning with Spark MLlib
Apache Spark 2.4
@jaceklaskowski / StackOverflow / GitHub
Books: Mastering Apache Spark / Mastering Spark SQL / Spark Structured Streaming
Spark MLlib
- Spark library for distributed machine learning
- Simplifies the development and usage of large-scale machine learning
- Uses Spark SQL for data access
- org.apache.spark.ml is the primary API
- The MLlib RDD-based API is now in maintenance mode
- Avoid the RDD-based MLlib API in org.apache.spark.mllib package
Features of Spark MLlib
- Machine learning algorithms
- Classification, regression, clustering, collaborative filtering
- Featurization
- Feature extraction, transformation, dimensionality reduction, selection
- Pipelines
- Constructing, evaluating, and tuning machine learning pipelines
- Persistence
- Saving and loading algorithms, models, and pipelines
- Utilities
- Linear algebra, statistics, data handling
Motivation
Predictive analytic workflow
- Use of a machine learning algorithm is only one component of a predictive analytic workflow
- There may also be pre-processing steps for the machine learning algorithm to work
- Expectations of data scientists and data engineers
Typical machine learning workflow
- Loading data (aka data ingestion)
- Preparing data (aka data cleanup)
- Extracting features (aka feature extraction)
- Fitting model (aka model training)
- Scoring (or predictionize)
Before Going To Production
- Testing model (aka model testing)
- Selecting the best model (aka model selection or model tuning)
- Deploying model (aka model deployment and integration)
ML Pipeline
Goal of ML Pipeline
Assemble and configurepractical distributed machine learning pipelines
as easy-to-use pieces
to compose more complex ones with ease (like Lego™ blocks)
Features of ML Pipeline
- DataFrame as a dataset format
- ML Pipelines API is similar to scikit-learn
- Easy debugging (via inspecting columns added during execution)
- Parameter tuning
- Compositions (to build more complex pipelines out of existing ones)
Components of ML Pipeline
- Pipelines and PipelineStages
- Transformers
- Estimators
- Models
- Evaluators
- Cross Validators
- Params and ParamMaps
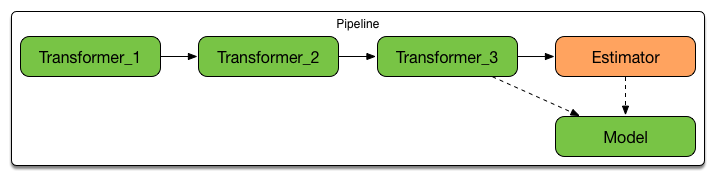
ML Pipeline Design
- Choose Transformers
- Select Estimator (to produce a Model)
- Create Pipeline
- Fit the pipeline to a training Dataset
- Use the Model
ML Pipeline Design Applied - Step 1
- Selecting Estimator (to produce a Model)
ML Pipeline Design Applied - Step 2
- Selecting Transformers (for feature selection)
ML Pipeline Design Applied - Step 3
- Creating Pipeline
- new Pipeline()
- setStages
ML Pipeline Design Applied - Step 4
- Fitting a model
- Requires a training Dataset
- Pipeline.fit
ML Pipeline Design Applied - Step 5
- Using trained Model (to generate predictions)
- Requires a real Dataset
- Pipeline.transform