![]()
![]()

ML Pipelines
Apache Spark 2.4 / Spark MLlib
@jaceklaskowski / StackOverflow / GitHub / LinkedIn
The "Internals" Books: Apache Spark / Spark SQL / Spark Structured Streaming / Delta Lake
ML Pipelines (spark.ml)
- DataFrame-based API under spark.ml package.
import org.apache.spark.ml._- spark.mllib package obsolete (as of Spark 2.0)
- Switch to The Internals Of Apache Spark
text document pipeline
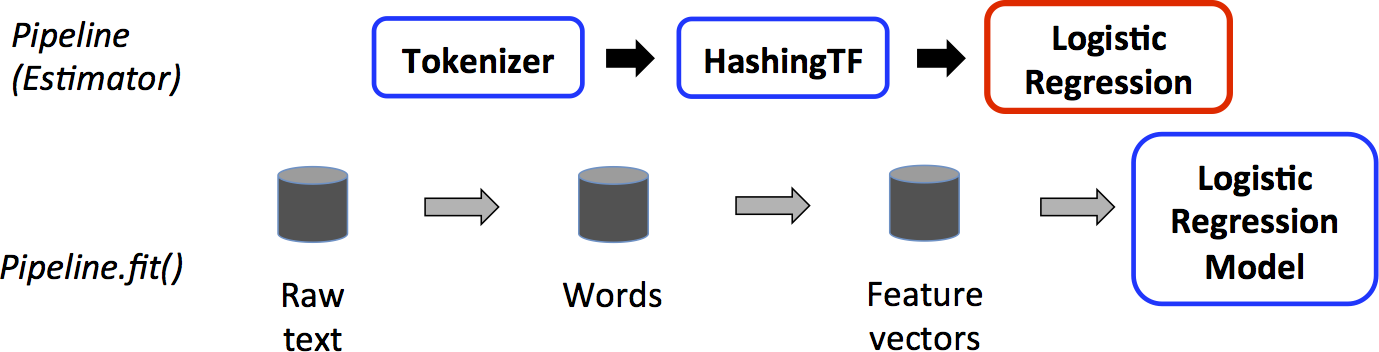 From the official documentation of Apache Spark
From the official documentation of Apache Spark
Transformers
- Transformer transforms DataFrame into "enhanced" DataFrame.
transformer: DataFrame =[transform]=> DataFrame - Switch to The Internals Of Apache Spark
Estimators
- Estimator produces Model (Transformer) for training DataFrame
estimator: DataFrame =[fit]=> Model - Switch to The Internals Of Apache Spark
Models
- Model - transformer that generates predictions for DataFrame
model: DataFrame =[predict]=> DataFrame (with predictions) - Switch to The Internals Of Apache Spark
text document pipeline model
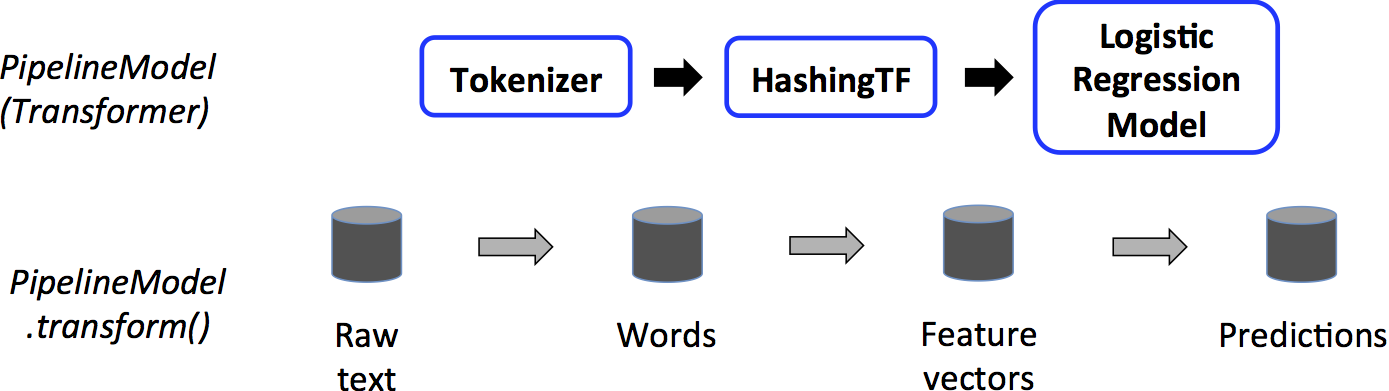 From the official documentation of Apache Spark
From the official documentation of Apache Spark
Evaluators
- Evaluator - transformation that measures effectiveness of Model, i.e. how good a model is.
evaluator: DataFrame =[evaluate]=> Double - Switch to The Internals Of Apache Spark
CrossValidator
- CrossValidator - estimator that gives the best Model for parameters
import org.apache.spark.ml.tuning.CrossValidator - Switch to The Internals Of Apache Spark
Persistence — MLWriter and MLReader
- Allows saving and loading models
model.write .overwrite() .save("/path/where/to/save/model")val model = PipelineModel.load("/path/with/model") - Switch to The Internals Of Apache Spark