![]()

The Core of Apache Spark
Apache Spark 2.4.1 / Spark Core
@jaceklaskowski / StackOverflow / GitHub
The "Internals" Books: Apache Spark / Spark SQL / Spark Structured Streaming
SparkContext — The Entry Point to Spark Services
- SparkContext is the entry point to the Spark services in your Spark application
- SparkContext manages the connection to a Spark execution environment
- Defined using the master URL
- Switch to Mastering Apache Spark 2
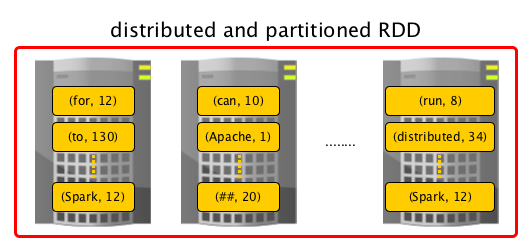
Partitions
- Partitions are logical buckets for data.
- Partitions correspond to Hadoop's splits (if the data lives on HDFS) or partitioning schemes in the source storage
- RDD (and hence the data inside) is partitioned.
- Spark manages data using partitions that helps parallelize distributed data processing with minimal network traffic for sending data between executors.
- Data in partitions can be skewed, i.e. unevenly distributed across partitions.
RDD Operators
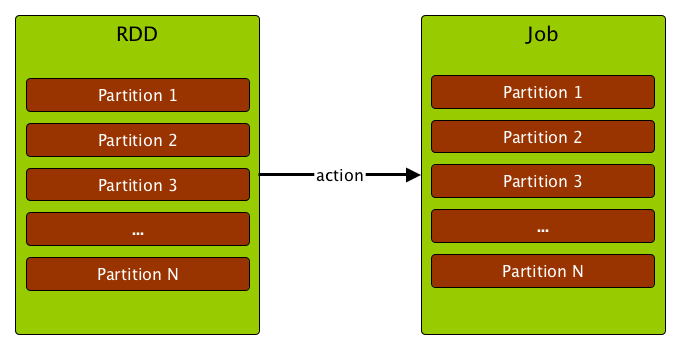
- Transformation is a lazy RDD operation that creates one or many RDDs
- Action is a RDD operation that produces non-RDD Scala values
- Switch to Mastering Apache Spark 2
Shuffle
- Shuffle is Spark's mechanism for re-distributing data so that it’s grouped differently across partitions.
- Data is often distributed unevenly across partitions.
- repartition and coalesce operators can repartition a dataset.
- Switch to Mastering Apache Spark 2
DAGScheduler
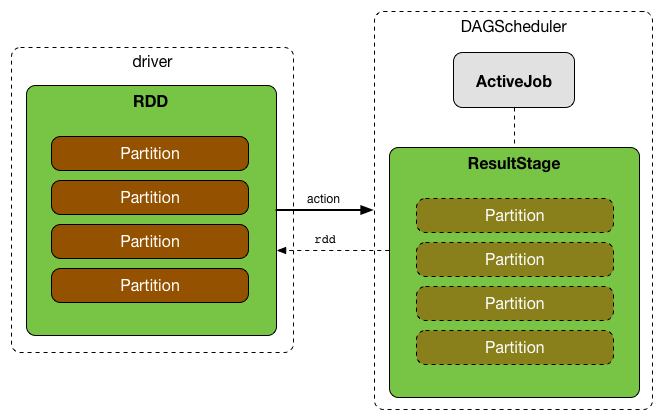
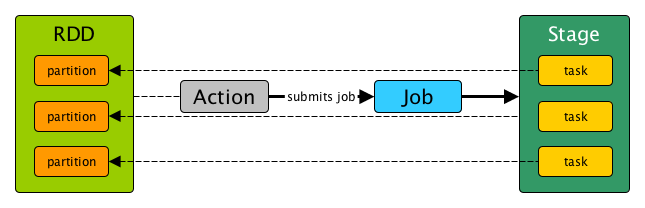
Jobs
Stages
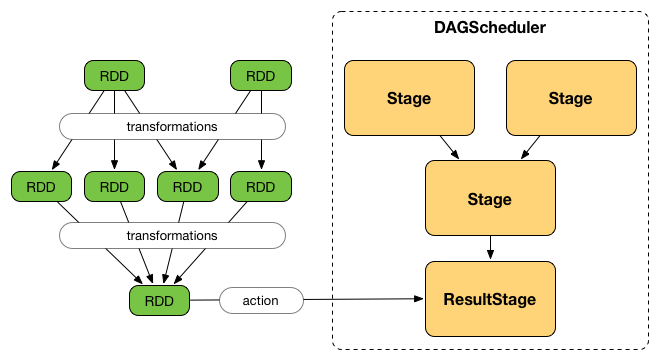
Tasks