![]()

Introduction to
Apache Spark
Apache Spark 2.4.0
@jaceklaskowski / StackOverflow / GitHub
The "Internals" Books: Apache Spark / Spark SQL / Spark Structured Streaming
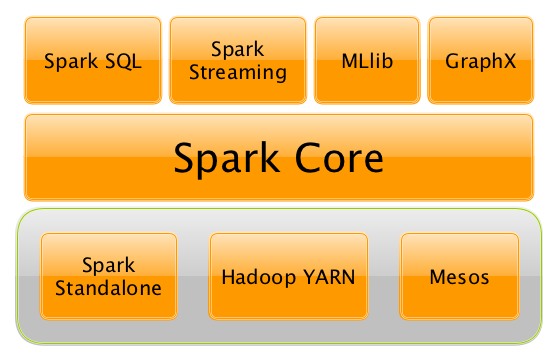
Spark Core
- RDD is the main abstraction of Apache Spark
- Resilient
- Distributed
- Dataset
- In-Memory, Immutable, Lazy Evaluated, Partitioned, Cacheable, Parallel, Typed
- CAUTION: Don't use directly. Too low-level. Leave it alone until you really really want it. Even then, think twice.
Spark SQL
- Distributed SQL Engine for Structured Data Processing
- SQL Interface
- Dataset and DataFrame
- DataFrame is a type alias for Dataset of Rows.
- Query DSL
- Hive Support
- UDF - User-Defined Functions
- Aggregation and Window Operators
Spark MLlib
- Large-Scale Distributed Machine Learning
- "Making practical machine learning scalable and easy"
- DataFrame-based API
- Pipeline API for designing, evaluating, and tuning machine learning pipelines
- Classification, Regression, Clustering, Recommendation, Collaborative Filtering, ...
- Model Import / Export
Spark Structured Streaming
Tools
- spark-shell - an interactive shell for Apache Spark
- spark-submit - a tool to manage Spark applications (i.e. submit, kill, status)
- spark-sql - an interactive shell for Spark SQL and Hive queries
- web UI - a web interface to monitor Spark computations
- Scala API for Apache Spark
- Spark Python API Docs