Demo: Using Cloud Storage for Checkpoint Location in Spark Structured Streaming on Google Kubernetes Engine¶
This demo is a follow-up to Demo: Running Spark Structured Streaming on minikube and is going to show the steps to use a persistent disk Google Cloud Storage for a checkpoint location in a Spark Structured Streaming application on Google Kubernetes Engine.
The demo uses the Cloud Storage connector that lets Spark applications access data in Cloud Storage using the gs:// prefix.
.option("checkpointLocation", "gs://spark-checkpoint-location/")
The most challenging task in the demo has been to include necessary dependencies in a Docker image to support the gs:// prefix.
Before you begin¶
It is assumed that you have finished the following:
- Demo: Running Spark Structured Streaming on minikube
- Demo: Running Spark Examples on Google Kubernetes Engine
Environment Variables¶
You will need the following environment variables to run the demo. They are all in one section to find them easier when needed (e.g. switching terminals).
export PROJECT_ID=$(gcloud info --format='value(config.project)')
export GCP_CR=eu.gcr.io/${PROJECT_ID}
export CLUSTER_NAME=spark-examples-cluster
# Has to end with /
export BUCKET_NAME=gs://spark-on-kubernetes-2021/
export K8S_SERVER=$(kubectl config view --output=jsonpath='{.clusters[].cluster.server}')
export POD_NAME=spark-streams-google-storage-demo
export SPARK_IMAGE=$GCP_CR/spark-streams-google-storage-demo:0.1.0
export K8S_NAMESPACE=spark-demo
export SUBMISSION_ID=$K8S_NAMESPACE:$POD_NAME
export KEY_JSON=spark-on-kubernetes-2021.json
export MOUNT_PATH=/opt/spark/secrets
Build Spark Application Image¶
List images and make sure that the Spark image is available. If not, follow the steps in Demo: Running Spark Examples on Google Kubernetes Engine.
gcloud container images list --repository $GCP_CR
gcloud container images list-tags $GCP_CR/spark
Go to your Spark application project and build the image.
sbt spark-streams-demo/docker:publishLocal spark-streams-google-storage-demo/docker:publishLocal
docker images $GCP_CR/spark-streams-google-storage-demo
REPOSITORY TAG IMAGE ID CREATED SIZE
eu.gcr.io/spark-on-kubernetes-2021/spark-streams-google-storage-demo 0.1.0 b9dd310765ba 3 minutes ago 542MB
docker tag
Use docker tag unless you've done it already at build time.
docker tag spark-streams-google-storage-demo:0.1.0 $GCP_CR/spark-streams-google-storage-demo:0.1.0
Push Image to Container Registry¶
Use docker image push to push the Spark application image to the Container Registry on Google Cloud Platform.
docker push $GCP_CR/spark-streams-google-storage-demo:0.1.0
Display Images¶
List the available images.
gcloud container images list --repository $GCP_CR
NAME
eu.gcr.io/spark-on-kubernetes-2021/spark-streams-google-storage-demo
Create Kubernetes Cluster¶
Create a Kubernetes cluster as described in Demo: Running Spark Examples on Google Kubernetes Engine.
gcloud container clusters create $CLUSTER_NAME \
--cluster-version=latest
Wait a few minutes before the cluster is ready.
In the end, you should see the messages as follows:
kubeconfig entry generated for spark-examples-cluster.
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS
spark-examples-cluster europe-west3-b 1.18.15-gke.1100 34.107.115.78 e2-medium 1.18.15-gke.1100 3 RUNNING
Create Cloud Storage Bucket¶
Quoting Connecting to Cloud Storage buckets:
Cloud Storage is a flexible, scalable, and durable storage option for your virtual machine instances. You can read and write files to Cloud Storage buckets from almost anywhere, so you can use buckets as common storage between your instances, App Engine, your on-premises systems, and other cloud services.
Tip
You may want to review Storage options for alternative instance storage options.
gsutil mb -b on $BUCKET_NAME
List Contents of Bucket¶
gsutil ls -l $BUCKET_NAME
There should be no output really since you've just created it.
Run Spark Structured Streaming on GKE¶
Create Kubernetes Resources¶
Create Kubernetes resources as described in Demo: Running Spark Examples on Google Kubernetes Engine.
k create -f k8s/rbac.yml
namespace/spark-demo created
serviceaccount/spark created
clusterrolebinding.rbac.authorization.k8s.io/spark-role created
Create Service Account Credentials¶
As the Spark application will need access to Google Cloud services, it requires a service account.
Tip
Learn more in Authenticating to Google Cloud with service accounts tutorial. The most important section is Creating service account credentials.
You should have a JSON key file containing the credentials of the service account to authenticate the application with.
Import Credentials as Kubernetes Secret¶
Tip
Learn more in Authenticating to Google Cloud with service accounts tutorial. The most important section is Importing credentials as a Secret.
The recommended way of using the JSON key file with the service account in Kubernetes is using Secret resource type.
kubectl create secret generic spark-sa \
--from-file=key.json=$KEY_JSON \
-n $K8S_NAMESPACE
Configure Spark Application with Kubernetes Secret¶
Tip
Learn more in Authenticating to Google Cloud with service accounts tutorial. The most important section is Configuring the application with the Secret.
In order to use the service account and access the bucket using gs:// URI scheme you are going to use the following additional configuration properties:
--conf spark.kubernetes.driver.secrets.spark-sa=$MOUNT_PATH
--conf spark.kubernetes.executor.secrets.spark-sa=$MOUNT_PATH
--conf spark.kubernetes.driverEnv.GOOGLE_APPLICATION_CREDENTIALS=$MOUNT_PATH/key.json
--conf spark.kubernetes.executorEnv.GOOGLE_APPLICATION_CREDENTIALS=$MOUNT_PATH/key.json
--conf spark.hadoop.google.cloud.auth.service.account.json.keyfile=$MOUNT_PATH/key.json
Submit Spark Application¶
Submit the Spark Structured Streaming application to GKE as described in Demo: Running Spark Structured Streaming on minikube.
You may optionally delete all pods (since we use a fixed name for the demo).
k delete po --all -n $K8S_NAMESPACE
./bin/spark-submit \
--master k8s://$K8S_SERVER \
--deploy-mode cluster \
--name $POD_NAME \
--class meetup.SparkStreamsApp \
--conf spark.kubernetes.driver.request.cores=400m \
--conf spark.kubernetes.executor.request.cores=100m \
--conf spark.kubernetes.container.image=$SPARK_IMAGE \
--conf spark.kubernetes.driver.pod.name=$POD_NAME \
--conf spark.kubernetes.namespace=$K8S_NAMESPACE \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \
--conf spark.kubernetes.submission.waitAppCompletion=false \
--conf spark.kubernetes.driver.secrets.spark-sa=$MOUNT_PATH \
--conf spark.kubernetes.executor.secrets.spark-sa=$MOUNT_PATH \
--conf spark.kubernetes.driverEnv.GOOGLE_APPLICATION_CREDENTIALS=$MOUNT_PATH/key.json \
--conf spark.kubernetes.executorEnv.GOOGLE_APPLICATION_CREDENTIALS=$MOUNT_PATH/key.json \
--conf spark.hadoop.google.cloud.auth.service.account.enable=true \
--conf spark.hadoop.google.cloud.auth.service.account.json.keyfile=$MOUNT_PATH/key.json \
--conf spark.hadoop.fs.gs.project.id=$PROJECT_ID \
--verbose \
local:///opt/spark/jars/meetup.spark-streams-demo-0.1.0.jar $BUCKET_NAME
Installing Google Cloud Storage connector for Hadoop
Learn more in Installing the connector.
Monitoring¶
Watch the logs of the driver and executor pods.
k logs -f $POD_NAME -n $K8S_NAMESPACE
Observe pods in another terminal.
k get po -w -n $K8S_NAMESPACE
Google Cloud Console¶
Review the Spark application in the Google Cloud Console of the project:
- Workloads
- Services & Ingress
- Configuration (make sure to use
spark-demonamespace)
Services & Ingress¶
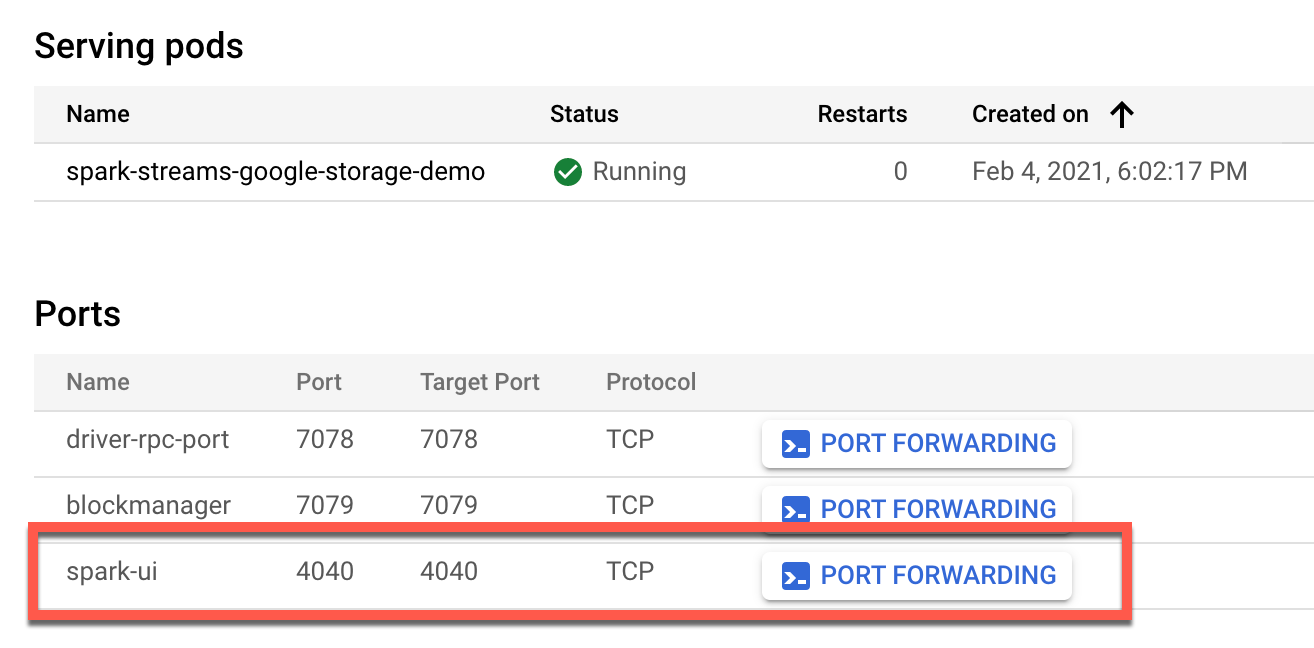
While in Services & Ingress, click the service to enable Spark UI.
-
Go to Service details and scroll down to the Ports section.
-
Click PORT FORWARDING button next to spark-ui entry.
Kill Spark Application¶
In the end, you can spark-submit --kill the Spark Structured Streaming application.
./bin/spark-submit \
--master k8s://$K8S_SERVER \
--kill $SUBMISSION_ID
Clean Up¶
Delete the bucket.
gsutil rm -r $BUCKET_NAME
Delete cluster resources as described in Demo: Running Spark Examples on Google Kubernetes Engine.
That's it. Congratulations!